01从“词袋”到“低维语义向量”
传统文本相似度算法,先把句子拆成词,再把词映射成向量,最后累加或拼接。
DSSM(Deep Structured Semantic Models)却换了一条路:它直接把整句扔进深度网络,输出一个固定维度的低维语义向量,两句话的“亲密度”就靠这两个向量在空间里的距离说了算。
02DSSM到底怎么“炼”出来的?
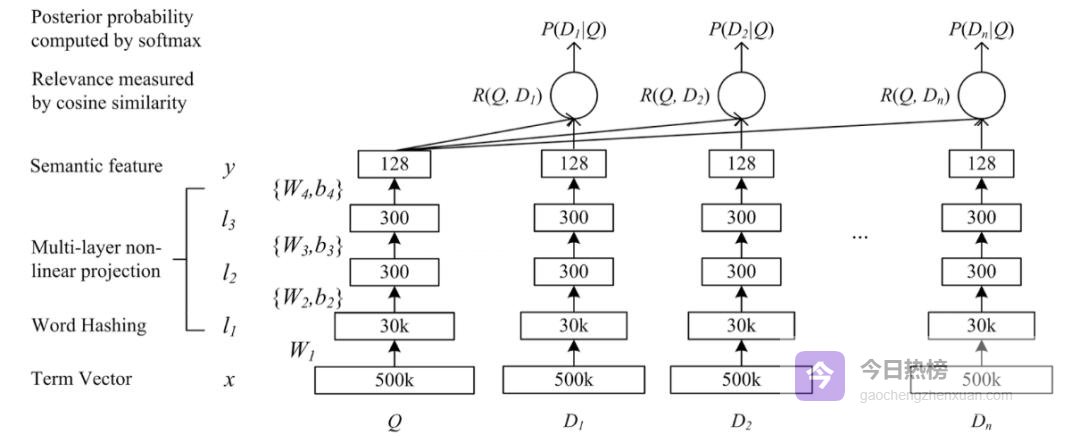
2.1 > 架构拆解:五层“压路机”Term Vector:把文本做One-hot,维度≈50万,稀疏又庞大。
Word Hashing:用3-gram把单词切成小片,再把“#-b-o, b-o-y, o-y-#”这类trigram拼回去,50万→3万,空间瞬间瘦身,还能把前缀、后缀的语义“打包”进同一个向量。
Multi-layer nonlinear projection:三层DNN继续压榨维度,3万→300→128,把语义浓缩成128个数。
Relevance:把Query的128维向量与每个Doc的128维向量做cosine,得到“一眼看上去像不像”的原始分数。
Softmax:把原始分数归一化成0~1的概率,越接近1说明越像点击的文档。
模型把“用户点了哪篇文档”当成标签,有监督学习让网络知道:当Query是“北京房价”,Doc里出现“首付300万”比出现“学区房”更值得被点击。
最终损失函数就是点击概率的对数似然,网络越“懂”用户,损失就越小。
03优点与痛点:一眼看穿DSSM
优点
无切词依赖:汉字向量可复用,外文也能直接上。
端到端有监督:拒绝中间环节的无监督误差,精度往往比传统方法高一个量级。
痛点
语序全丢:BOW模型把顺序洗成袋子,时态、上下文全糊在一起。
结果不可解释:黑箱模型,改一行参数可能让整体效果“上天”或“入地”。
弱监督信号:点击数据里掺着搜索排序的“私货”,第一页被点击≠内容真的相关,标签噪音大。

04小结:DSSM不是万能钥匙,却是深度学习的“开门红”
当你想把句子压缩成“一串数字”,再让这串数字替你说“我们像不像”,DSSM提供了一条经过验证的捷径。
它让文本相似度计算从“词袋+统计”跃迁到“深度语义嵌入”,也为后续BERT、GPT等模型提供了有监督微调的思路——先让人工标注少量数据,再用大模型把知识蒸馏出来。
原创文章,作者:郭峰,如若转载,请注明出处:http://m.gaochengzhenxuan.com/news/620.html