2026年初,Meta Platforms宣布一项震撼业界的计划:将在未来数年内部署数百万颗英伟达AI芯片,涵盖Blackwell架构及下一代Vera Rubin平台。这不仅是科技巨头对算力的空前押注,更揭示了一个清晰战略——构建支撑“个人超级智能”的基础设施。消息一出,英伟达股价盘后上涨超1%,而竞争对手AMD应声下跌3%。市场用脚投票,显示出对这场深度绑定的看好。

这场合作远非简单的采购关系。Meta已是英伟达芯片的第二大客户,此次则将合作推向新高度:首次大规模采用纯英伟达Grace CPU平台,并全面整合其从GPU、CPU到互连、网络的全栈技术。这意味着Meta正逐步将自身AI基础设施“英伟达化”,打造一个高度协同、软硬一体的计算体系。
为何是现在?答案藏在AI进化的底层逻辑中。当前大模型已从“感知智能”迈入“认知智能”阶段,DeepSeek-R1等具备复杂推理能力的模型成为主流。这类模型不仅参数庞大,更依赖长上下文、多步骤逻辑和稀疏激活的MoE架构。传统计算架构难以高效支撑,GPU与CPU之间的数据搬运成为瓶颈。Meta需要的不再是零散算力,而是一套能持续支撑智能跃迁的“超级引擎”。
英伟达Blackwell架构正是为此而生。其核心创新之一是第二代Transformer引擎,首次在硬件层面支持FP4精度运算,使计算密度提升4倍。更重要的是,它能硬件加速MoE模型的专家路由,将延迟从12微秒压缩至3微秒。实测显示,在处理128k上下文推理任务时,Blackwell单卡吞吐量比前代H100提升超3倍,能效比提高2.4倍。这对Meta意义重大——意味着其AI助手、推荐系统等关键服务可实现毫秒级响应。

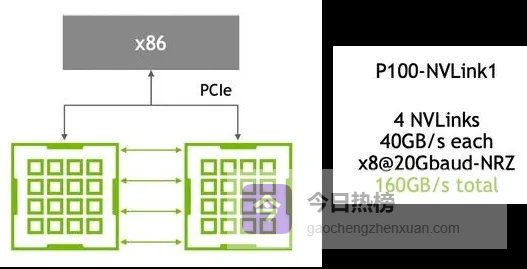
另一个关键突破是NVLink 5.0。单颗GPU通过18条链路实现1800GB/s的互联带宽,是PCIe 5.0的14倍。在此基础上构建的DGX GB200 NVL72系统,可将72块B200 GPU全互联,单机架带宽超1PB/s,内存总量达240TB。Meta利用这一架构,已将复杂模型训练周期从72小时缩短至8小时,效率提升90%。这种规模效应,正是支撑数十亿用户级AI服务的基础。

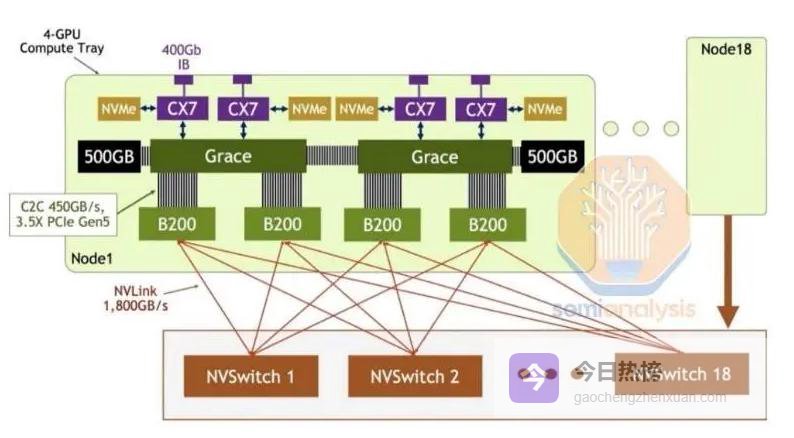
但Meta的目光不止于当下。其合作范围明确包含尚未发布的Vera Rubin架构。这一平台并非单一芯片,而是由六款协同设计的芯片组成的“AI超级计算机”。其中,新一代Rubin GPU算力预计达50 PFLOPS,较Blackwell提升5倍;HBM4内存带宽高达22TB/s,几乎消除内存墙。更关键的是,平台引入专为AI推理设计的Vera CPU,通过NVLink-C2C实现最高3.6TB/s的互联带宽,使CPU可作为GPU的“显存扩展池”,协同处理长上下文任务。

这解释了Meta为何首次大规模部署纯Grace CPU平台。传统服务器中,CPU只是GPU的“供料员”,受限于PCIe带宽,常导致GPU“饥饿”。而Grace CPU通过NVLink与GPU深度集成,共享统一内存空间,带宽高达900GB/s,是PCIe的30倍。它不再被动调度,而是作为“智能中枢”,直接参与上下文管理、数据预处理等任务。这种架构下,GPU利用率显著提升,系统整体能效比优化10倍以上。
对用户而言,这场算力革命的最终落点是“个人超级智能”——扎克伯格设想中,每个人都能拥有一个理解其习惯、能自主完成复杂任务的AI伙伴。这需要模型具备持续学习、跨应用协同和高度个性化能力,背后是指数级增长的算力需求。Meta的部署,正是为这一愿景铺路。未来,用户与AI的每一次交互,都可能调用数颗Blackwell或Rubin芯片的协同计算。
展望未来,这场合作或将重塑AI基础设施格局。英伟达正从GPU供应商转型为全栈系统提供商,而Meta则通过深度绑定,锁定最前沿算力资源。随着Vera Rubin平台在2026年逐步落地,推理token成本有望降至当前的十分之一,推动AI服务进一步普及。但挑战亦存:如此庞大的芯片需求可能加剧全球供应链压力,而高度集中的技术依赖,也引发外界对生态多样性的担忧。

无论如何,Meta与英伟达的联手,标志着AI竞赛进入新阶段——胜负不再仅由算法决定,更取决于谁掌握构建“AI工厂”的能力。在这场算力基建的长跑中,芯片已不仅是硬件,而是通向智能未来的通行证。
原创文章,作者:胡佳慧,如若转载,请注明出处:http://m.gaochengzhenxuan.com/yule/5416.html


